
Be Joyful!
코드스테이츠 PMB 10기 | 2주 전의 나를 돌아보며, 망고플레이트 다시 분석하기 본문
오늘은 데이터와 개발의 매운맛에 굴복했던 지난주 과제를 회고하는 시간을 가져볼 예정입니다.
지난주 제가 선정한 프로덕트는 맛집 검색 어플, 망고플레이트입니다. 지난 과제에는 서비스 일부분의 플로우를 흐름도로 구성하고, 클라이언트와 서버의 작동 방식과 데이터 수집 방식을 개략적으로 추정해보았습니다.
그리고 6-7주차에 학습한 내용을 바탕으로 지난 과제에서 다소 아쉬웠던 부분을 아래와 같이 정리해보았습니다.
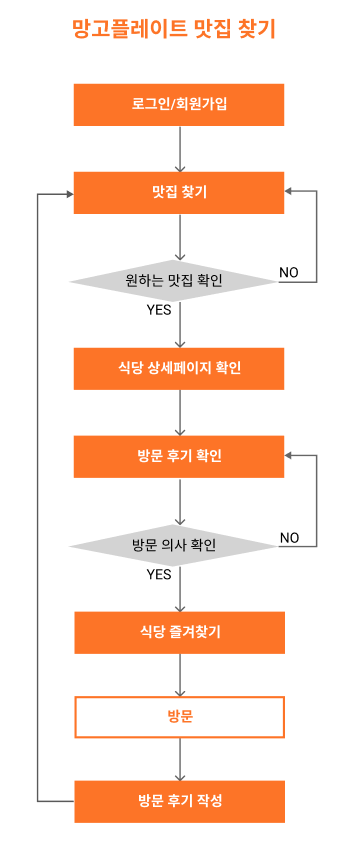
전체 흐름을 보지 못한 플로우 차트
당시 플로우 차트를 그리는 것 자체에 집중하다보니, 로그인, 맛집 검색 등 지극히 일부 기능에만 초점을 맞춰 흐름도를 작성했습니다. 망고플레이트가 제공하는 서비스 중 극히 일부에 불과하기 때문에 전반적인 플로우를 확인할 수 없다는 점이 아쉬웠습니다.
<AS-IS>


<TO-BE>
UI / 클라이언트 / 서버 살펴보기
API의 역할을 간과했구나...!
당시 API의 기능과 역할에 대해 제대로 파악하지 못한채 과제를 수행했습니다. 하여, 클라이언트와 서버가 작동하는 과정을 추정하였을 당시, API의 역할을 간과했다는 점을 새로 알게 되었습니다.
망고플레이트의 '맛집 찾기' 기능을 이용하기 위해서는 다양한 요청과 응답의 과정이 이뤄질 것이며, 이 과정을 효율적으로 처리하기 위해 다양한 API가 활용되었을 것입니다. 플로우차트를 기반으로 어떤 기능이 실행되는지 파악한 후 그에 따라 어떤 API가 활용되고 있을지 추정해 볼 수 있습니다.
로그인/회원가입 단계
망고플레이트에서는 간편로그인 서비스를 지원하고 있습니다. 이를 통해 간편 로그인 API가 활용되고 있음을 추정할 수 있습니다. 그리고 카카오톡 개발 가이드를 참고하여 요청과 응답이 어떤 과정으로 이루어지는지 파악할 수 있었습니다.


- 사용자가 간편 로그인 버튼을 클릭하면 카카오 계정의 자격정보를 통해 사용자를 인식합니다.
- 자격 정보가 올바르다면 사용자에게 정보 및 기능 활용 동의를 요청합니다.
- 사용자가 필수 항목에 동의하고 로그인을 요청하면 인증 코드가 발급됩니다.
- 해당 인증 코드를 기반으로 ACCESS TOKEN을 부여받아 유효성 확인 후 응답이 전달됩니다.
맛집 찾기
망고플레이트의 핵심이 되는 '맛집 찾기' 기능은 위치 기반 맛집 정보를 제공합니다. 아래와 같이 식당 상세페이지뿐만 아니라, 지도 검색 기능 등 지도 API를 활용해 다양한 기능을 활용할 수 있음을 알 수 있었습니다.

실제로 네이버 클라우드 플랫폼 공식 블로그 글을 확인한 바로는 망고플레이트는 NAVER MAPS Enterprise API를 사용하고 있음을 알 수 있었습니다. 이를 통해 인터랙티브가 가능한 동적 지도부터, 경로 관련 정보, 위치 데이터를 이용한 장소 정보 제공까지 맛집 검색에 활용할 수 있는 다양한 데이터를 제공합니다.

· Use Case: 지도 위에서 *POI 정보를 보여주는 서비스를 제공하고 있으며, *URL Scheme을 이용해 네이버 길찾기가 지원됩니다.
*POI (Point Of Interest): 관심지점, 관심지역정보
*URL Scheme: “http://”, “ftp://”, “market://”과 같은 문자열을 url scheme이라 부름
이외에도 맛집 리스트를 불러오는 API, 검색 기능 API, 리뷰 API 등 맛집 정보를 탐색하기 위한 다양한 API가 활용되었으리라 추정됩니다.
※ 그러나 여전히 남는 의문점
네이버 지도 api와 구글 지도 api, 두 개가 연동된 것으로 보인다. 왜 한 앱에 두 가지 지도 api를 사용했을까?
두 API가 제공하는 기능에 차이가 있지 않을까 싶지만, 상세한 내용은 파악하지 못했습니다. 추후 기회가 된다면 두 지도 API의 차이를 한 번 알아보고 싶습니다.
데이터 베이스는 어떻게 생겼을까?
지난 과제에는 관계형 데이터베이스가 어떻게 구성되겠다... 하는 점을 초등학생 수준으로 살펴봤습니다.

위 표는 이해를 돕기 위해 직접 제작해 본 허접용 테이블이며, 실제 데이터베이스의 구조를 확인하기 위해서는 ERD(entity-relationship diagram)를 사용합니다.
ERD는 개체 속성과 개체 간 관계를 도표로 표현한 것을 의미하며, 이는 데이터의 관계를 파악하는데 매우 용이합니다. 저는 ERD 제작 툴 중 AQueryTool을 이용해 데이터베이스의 기본 테이블 구조를 확인했습니다.
AQueryTool
{{source.erd_info.erd_name + '(Ver ' + erdVersion + ', ' + source.erd_info.db_type + ')'}}
aquerytool.com

데이터베이스는 다음과 같은 테이블간의 관계 설정을 통해 구성되며, 각각의 항목이 의미하는 바는 아래와 같습니다.
- Table name: 테이블 이름
- Table logical name: 테이블 상세 설명
- PK(Primary Key): 기본키
- AI(Auto Increment): 숫자 자동 증가 여부
- FK(Foreign Key): 외래키
- Null: Null값 허용 여부
- Logical Name: Column 설명
- Name: Column 이름
- Type: 데이터 타입
- INT: ID 또는 정수로 딱 떨어지는 숫자를 저장할 때 사용
- VARCHAR(45): 길지 않은 문자열을 저장할 때 사용. 괄호 안의 숫자는 Max length.
- TEXT: 긴 문자열 저장 시 사용
- DATETIME: 날짜와 시간을 함께 저장할 때 사용
- DECIMAL(18,0): 소수점 n째 자리까지 표기할 때 주로 사용
아래 ERD는 망고플레이트 클론앱 프로젝트를 진행하신 개발자님께서 깃허브에 업로드하신 ERD 자료입니다. 식당 정보, 유저 정보, 리뷰 정보 등의 다양한 정보가 10여 개의 테이블로 나뉘어져 있으며, 관계형으로 설정되어 각각의 정보가 연결되고 있음을 알 수 있었습니다.

지금도 개린이 수준에서 벗어나지는 못했지만, 그래도 2주간 학습을 거듭하며 이전 과제에 빠진 개념이 무엇인지 스스로 파악할 수 있었습니다. 여전히 개발이나 데이터는 어렵지만 그래도 외계어처럼 아예 이해가 불가능한 수준은 벗어난 것 같으므로, 더욱 학습에 박차를 가하며 실무에 원활히 적용할 수 있도록 해야겠습니다.
참고 자료
https://velog.io/@tmdgusya/DB-%EC%8A%A4%ED%82%A4%EB%A7%88-%EC%84%A4%EA%B3%84
DB 스키마 설계
스키마 설계 방법론 이게 정말 어려운 것 같다. 어떻게 하면 사용자의 요구사항에 맞게 데이터 베이스 스키마를 설계 할 수 있을까? 오늘은 데이터 베이스 개론이라는 책에 나와 있는 그 방법론
velog.io
https://github.com/nameunji/project_wegoplate_backend
GitHub - nameunji/project_wegoplate_backend
Contribute to nameunji/project_wegoplate_backend development by creating an account on GitHub.
github.com
'PMB 10 Daily - 매일매일 성장기록' 카테고리의 다른 글
| 코드스테이츠 PMB 10기 | Agile & Scrum, 그것이 알고싶다. (0) | 2022.03.15 |
|---|---|
| 코드스테이츠 PMB 10기 | #인스타그램 #해시태그 #여러개 #한번에 #검색하게 #해주세요 (0) | 2022.03.15 |
| 코드스테이츠 PMB 10기 | 개알못의 눈으로 살펴본 API (2) | 2022.03.10 |
| 코드스테이츠 PMB 10기 | 하늘 아래 같은 앱은 없다. (2) | 2022.03.08 |
| 코드스테이츠 PMB 10기 | MBTI 과몰입 인간의 웹 개발 3대장 파헤치기 (6) | 2022.03.05 |



